


Sorgu Performansını Artırmak için: Index Kullanımı
Index’ler veritabanındaki sorguları çekerken hızlandırmak amacıyla kullandığı özel veri yapılarıdır. SQL index, kullanıcıların sık sık araması gereken kayıtları bulmak için kullanılan hızlı bir arama tablosudur. Index, küçük hızlı ve hızlı aramalar için optimize edilmiştir. İlişkisel tabloları bağlamak ve büyük tabloları aramak için çok kullanışlıdır.
Neden SQL Server Index Oluşturmalı
Indexler, veritabanından diğerlerinden daha hızlı veri almak için kullanılır. Kullanıcılar indexleri göremez, yalnızca aramaları / sorguları hızlandırmak için kullanılırlar.
Not: Bir tabloyu indexlerle güncellemek, tablo olmadan güncellemekten daha fazla zaman alır (çünkü indexlerin de güncellemeye ihtiyacı vardır).
Indexler, iyi veritabanı ve uygulama performansı elde etmek için çok önemlidir. Kötü tasarlanmış dizinler ve bunların eksikliği, düşük SQL Server performansının birincil kaynaklarıdır. Bu makalede, SQL server index en iyi duruma getirme sorgu performansını artırmak için nasıl bir yaklaşım izleyebiliriz onları öğreneceğiz.
Index, tablodan veya view satırların alınmasını hızlandıran tablodaki bilgilerin bir kopyasıdır. Bir indexin iki ana özelliği şunlardır:
- Smaller than a table(Bir tablodan daha küçük) – bu, SQL Server’ın dizini daha hızlı aramasına olanak tanır, bu nedenle bir sorgu tablomuzdaki belirli bir sütuna çarptığında ve bu sütunda bir index varsa, SQL Server tüm tabloyu aramak yerine dizini aramayı seçebilir çünkü dizin çok daha küçüktür ve bu nedenle daha hızlı taranabilir.
- Presorted(Önceden sıralanmış) – bu aynı zamanda aramanın daha hızlı gerçekleştirilebileceği anlamına gelir çünkü her şey önceden sıralanmıştır, örneğin “Z” harfiyle başlayan bir dize arıyorsak, SQL Sunucusu, arama ölçütlerinin nerede olacağını bildiği için aramayı bir dizinin altından başlatacak kadar akıllıdır.
Index Türleri
Genel olarak, SQL Server birçok index türünü destekler, ancak bu makalede, sizlere SQL Server’da bulunan index türleri hakkında genel bir anlayışa sahip olduğunu ve yalnızca SQL Server index optimizasyonu üzerinde en büyük etkiye sahip en çok kullanılanları listeleyeceğim. Tüm dizin türlerinin genel açıklaması için Microsoft’un sayfasını ziyaret edebilirsiniz bkz. Index Types
SQL Server’da 2 farklı Index yapısı mevcuttur. Clustered ve Non-Clustered Index
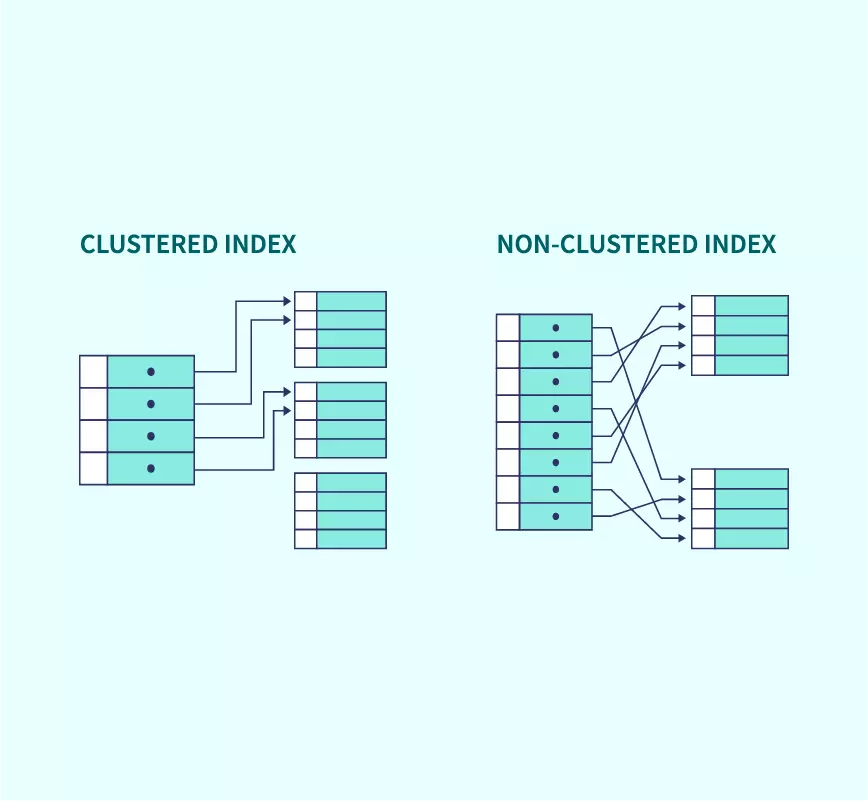
Clustered(Kümelenmiş): Verilerin diske nasıl yazılacağını belirler, örneğin bir tablonun kümelenmiş indexi yoksa, veriler SQL Server’ın erişmesini zorlaştıracak herhangi bir sırada yazılabilir, ancak mevcut olduğunda, kümelenmiş bir dizin tablonun veya görünümün veri satırlarını sayısal sıraya göre alfabetik olarak sıralar ve depolar. Bu nedenle, üzerinde kümelenmiş bir dizin bulunan bir kimlik alanımız varsa, veriler bu kimliğin sayısına göre diske yazılacaktır. SQL Server’ın verileri diskte fiziksel olarak tutabilmesinin yalnızca bir yolu olabilir ve bu nedenle tablo başına yalnızca bir kümelenmiş indexe izin verilir. Bilinmesi gereken önemli bir şey, kümelenmiş bir indexin birincil anahtarla otomatik olarak oluşturulmasıdır.
Non-Clustered(Kümelenmemiş):Kümelenmemiş – bu, SQL Server’daki en yaygın türdür ve genellikle tek bir tabloda birden fazladır. Kümelenmemiş indexlerin maksimum sayısı SQL Server sürümüne bağlı olarak değişir, ancak sayı örneğin SQL Server 2016’da tablo başına 999’a kadar çıkar. Verileri gerçekten düzenleyen kümelenmiş dizinlerin aksine, kümelenmemiş dizin biraz farklıdır. En iyi benzetme, onu bir kitap olarak düşünmek olacaktır. Bir kitabın en sonuna gidersek, genellikle temelde çok büyük bir konu listesine sahip olan ve hangi sayfada olduklarını gösteren bir index ekleme kısmı vardır. Tipik bir senaryo, okuyucunun bir konu / terim bulması ve örneğin sayfa 256’daki bir bölüme işaret etmesidir. Okuyucu o sayfaya giderse, aranan bilgi tam oradadır. Önemli olan, içeriği aramak için tüm kitabı gözden geçirmeye gerek kalmadan çok hızlı bir şekilde bulmaktır ve bu temelde kümelenmemiş dizinin yaptığı şeydir.
Nasıl Index Oluşturulur?
Şimdi, bazı temel bilgiler edindiğimize ve indexlerin ne işe yaradığına dair genel bir fikir edindiğimize göre, bir index oluşturmak için SQL Server Management Studio’yu (SSMS) kullanan birkaç SQL Server index optimizasyonu gerçek örneğini görelim ve en önemlisi indexlerin bazı performans avantajlarına daha yakından bakalım.
İlk olarak, bir test tablosu oluşturmamız ve içine bazı veriler eklememiz gerekir. Aşağıdaki örnek AdventureWorks2014 veritabanını kullanalım, ancak daha sonra silinebilecek yeni bir tablo oluşturduğumuzdan herhangi bir veritabanını da kullanabilirsiniz. Mevcut Person.Address tablosunun yepyeni bir kopyasını oluşturmak için kodu çalıştırın:
SELECT *
INTO Person.AddressIndexTest
FROM Person.Address a;
Person.AddressIndexTest adlı yeni bir tablo oluşturduk ve sorguyu yukarıdan yürüterek 19614 kayıt kopyaladık, ancak kaynak tablonun aksine, yeni taranan tablonun üzerinde kesinlikle index yok.
Şimdi, SSMS’deki yeni verileri sorgulayalım ve sonuç kılavuzunda döndürülen bilgileri nasıl analiz edebileceğimizi görelim. Sorguları analiz etmeden ve performans testinden önce aşağıdaki kodu kullanmanız gerekir:
CHECKPOINT;
GO
DBCC DROPCLEANBUFFERS;
DBCC FREESYSTEMCACHE('ALL');
GO
CHECKPOINT ve DBCC DROPCLEANBUFFERS sadece temiz bir sistem durumu oluşturuyor. Önbellekten mümkün olduğunca çok şey kaldıracaktır, çünkü performans testi yaparken her seferinde temiz bir bellek durumuyla başlamanız tavsiye edilir. Bu şekilde, performanstaki herhangi bir değişikliğin, önceki çalıştırmalarda önbelleğe alınmamış bazı verilerin önbelleğe alınmasından kaynaklanmadığını biliyoruz.
Aynı sorgunun diğer kısmı, yeni oluşturduğumuz tablodan bir sütun döndürdüğümüz Select deyimi olacaktır. Ancak Select deyiminin etrafına sarılmış, T-SQL deyimlerinin kendisi tarafından oluşturulan disk etkinliği miktarıyla ilgili bilgileri görüntülemek için SET STATISTICS IO’yu ekleyelim. Bu nedenle, ifadeyi yürüttüğümüzde, elbette bazı veriler döndürecektir, ancak ilginç kısım, tablonun kaputun altında nasıl sorgulandığını görebileceğimiz Mesajlar sekmesine geçtiğimizde 4400 veri eklendiğini görüyoruz.

Index oluşturmanın en kolay yolu tablonun içine tıklamak sonra indexin üstüne sağ tıklayıp new index>non-clustered index seçeneğini tıklıyoruz.

Bu, bu index bir sütun eklemek için sağ alttaki Ekle düğmesini tıklayabileceğimiz Yeni indexpenceresini açacaktır:

Bu örnekte, indexe eklenecek yalnızca bir sütuna ihtiyacımız vardır ve bu Select deyimindeki sütundur. Bu nedenle, AddressID tablo sütununu seçin ve devam etmek için Tamam düğmesine basın:

SQL Server index için otomatik olarak bir ad seçti ve gerekirse bu değiştirilebilir, ancak neden varsayılanlarla gitmiyorsunuz?
Index oluşturma işlemini tamamlamak için Tamam düğmesine bir kez daha basmanız yeterlidir:


Bu, tablo özellikleri penceresini açacak ve Storage sayfasına geçersek, tablodaki verilerin boyutunu megabayt cinsinden (bu durumda 2,711 MB) temsil eden bir Veri alanı öğesi vardır ve sorguyu dizin olmadan ilk kez çalıştırdığımızda, SQL Server tablodaki her satırı okumak zorunda kalmıştır, ancak dizin yalnızca 0,367 MB’dir.
Bu nedenle, indexi oluşturduktan sonra, SQL Server aynı sorguyu yalnızca indexi okuyarak yürütebilir, çünkü bu durumda index gerçek tablodan 7,3 kat daha küçüktür:

İstatistiklere de bakabiliriz. İstatistikler, veritabanı performans dünyasında önemli bir rol oynamaktadır. Index oluşturulduktan sonra, SQL Server otomatik olarak istatistikler oluşturur. Oluşturduğumuz Test index tablosuna dönün, tabloyu genişletin, İstatistikler klasörünü genişletin ve daha önce oluşturulan indexle tam olarak aynı ada sahip istatistiğe sağ tıklayın ve Özellikler’i seçin:

Bu aralıkların yüzlercesini tablolardaki istatistiklerde görürsünüz ve bu nedenle, SQL Server aranan değerlerin indexini en başında, ortasında veya sonunda olup olmadığını bilir ve bu nedenle index tamamını okuması gerekmez. Genellikle, bir yüzde oranında başlayacak ve sadece sonuna kadar okuyacaktır.
Dolayısıyla, bu iki faktör: bir dizin genellikle bir tablodan daha küçüktür ve istatistiklerin bir dizinde tutulması, SQL Sunucusunun aradığımız belirli verileri daha az kaynak kullanarak ve daha hızlı bir şekilde bulmasını sağlar.
Indexlerin, veriler bir veritabanından okunurken performans artışı sağladığını, ancak veriler yazılırken performans düşüşüne de yol açabileceğini unutmayın. Niçin? Çünkü bir tabloya veri eklerken, SQL Server’ın hem tabloyu hem de dizin değerlerini güncelleştirmesi ve yazma kaynaklarını artırması gerekir.
Genel kural, bir tablonun ne sıklıkta okunduğunun ve ne sıklıkta yazıldığının farkında olmaktır. Öncelikle salt okunur olan tablolar çok sayıda indexe sahip olabilir ve genellikle yazılan tabloların daha az dizine sahip olması gerekir.
Referanslar
https://www.mshowto.org/sql-server-index-yapisi-nedir-nasil-calisir-ne-ise-yarar.html
https://www.scaler.com/topics/clustered-and-non-clustered-index/
https://littlekendra.com/2016/01/28/how-to-check-if-an-index-exists-on-a-table-in-sql-server/