

SQL Server Execution Plan Nedir?
Merhabalar,
SQL Server, bildiğimiz üzere tablolar ve bu tablolar üzerinde yer alan dataların saklandığı bir yapıdır. Ve biz SQL Server ile iletişim kurmak istediğimizde bunu sorgular üzerinden o tablolara erişerek yapmaktayız. Yapılan sorgulamaların çoğunluğunu veri okuma işleminin oluşturduğunu düşündüğümüzde, son kullanıcıya istenilen verilerin en kısa sürede iletilmesi oldukça önemlidir.
İşte bu noktada SQL Server gelen sorguyu derler ve hangi tabloya gitmesi gerektiği, bu tabloya giderken (varsa) hangi indexi kullanacağı, hangi verileri alacağı ve bunları yaparken istatistiklerden yararlanmak gibi birçok detayı değerlendirir ve plan çıkarır. Arka planda yapmış olduğu bu değerlendirmeler sonrasında, sorgu sonucunu getirirken en az maliyetli planın hangisi olduğuna karar verir. Sorguyu yürütürken kullanacağı bu plana Execution Plan denir.
Execution Plan bir kere belirlendikten sonra cache’e alınır ve bir sorgu geldiğinde cachede tutulan planları tarayarak aynı ya da benzer sorgu mevcutsa o execution plan üzerinden sonuçları döndürür.
Bu yazımızda, hazırlamış olduğumuz sorgular için Execution Plan okurken sık karşılaştığımız operatörleri ve bu operatörlerin hangi sebeplerle karşımıza çıktığını inceleyeceğiz.
- Table Scan
- Clustered Index Scan
- Clustered Index Seek
- Nonclustered Index Scan&Seek
- Key Lookup
- RID Lookup
- Sort
Bu operatörleri açıklamaya başlamadan önce dikkat edilmesi gereken birkaç detay paylaşmak istiyorum.
İlk olarak index kullanımına değinelim. Tablolar üzerinde yer alan indexlerimizin sorgu performansına etkisi tartışılmaz bir gerçektir. Çünkü bu indexler tabloyu istediğimiz kolona göre sıralar ve o şekilde saklar. Biz sorgulama yapmak istediğimizde verdiğimiz koşullar için belirli algoritmalar üzerinden gider ve bize datayı getirir. Bunu kitaplarda yer alan “İçindekiler” bölümüne benzetebiliriz. Bir kitapta hangi sayfada hangi bilgilerin yer aldığı bu kısımda tutulmaktadır.
Performans ve hız açısından büyük avantajlar sağlasa da elimizdeki tabloyu istenilen kolona göre yeniden dizdiği için bazı dezavantajları da bulunmaktadır. Data diskinde tablo boyutuna ek olarak bir de index için ayrı bir yer tutar. Bu da diskin çabuk dolmasına sebebiyet verebilir. Bir diğer dezavantajı ise daha önceden tanımlanmış başka bir indeksi ezebileceği(kapsayacağı) için o indeksi boşa çıkarabilir. Aynı zamanda index için bir yol haritası dersek, hiç yol göstermemek bazen yanlış yol göstermekten daha iyi olabilir. O sebeple SQL Server’ın bize tavsiye ettiği her indexi tanımlamak, yolu uzatmamıza ve dolayısıyla veriye daha geç ulaşmamıza sebep olabilir. Detaylı analiz edilip ona göre tanımlanması daha sağlıklı olacaktır. Index kavramının birçok detayı olmasından dolayı yazımızda bu kadarına, ihtiyacımız doğrultusunda değinmek istedim.
Index kavramıyla birlikte önemli olan diğer kavram ise statistics kavramıdır. Tablolarda kaç satır veri olduğunu tahmini olarak tutar diyebiliriz. SQL Server sorgu çalıştırılacağı zaman bu statisticslere bakarak hangi yolu seçeceğini planlar.
Tabloda 100 satır olması ile 100000 satır olması arasında arka tarafta birçok fark vardır ve buna göre bir yol belirlenir. Statisticsler güncel değilse eğer tabloda 100 satır var gibi davranır ve ona göre execution plan oluşur. Sonra sorgunun neden geç geldiği ile ilgilenir dururuz. Fakat aradaki bu veri sayısı farkını SQL Server’a yeniden hatırlatırsak sorgumuz daha hızlı gelecektir. Yani statistics güncellemek “Yeni bilgi geldi haberin olsun. Ona göre kendine kestirme yol belirle.” demenin SQL deki karşılığıdır.
Bu detaylardan sonra artık Execution Plan’a dönebiliriz.
Execution Plan için iki farklı seçenek mevcuttur.
1.Estimated Execution Plan
Sorgumuz çalıştırılmadan, tahmini olarak izleyeceği yolu gösterir. İncelemek istediğiniz sorguyu seçerek Ctrl+L kısayolu ile görebilirsiniz.
2.Actual Execution Plan
Sorgunun çalıştırılması ile izlenen yoldur. Ctrl+M kısayolu ile bu seçeneği aktif ettikten sonra, sorgunuzu çalıştırarak inceleyebilirsiniz.
Not : Execution Plan okurken sırası ile yukarıdan aşağıya ve sağdan sola doğru takip edilir. Operatörler arası geçiş sırasında zaten oklar yer almaktadır. Bunları takip etmek amacıyla kullanabileceğiniz gibi diğer operatöre geçiş yaparken aktarılan verinin büyüklüğüyle ilgili bilgi sahibi olmak için de kullanabilirsiniz. Operatörün üzerine geldiğinizde beliren tooltip kısmından da bu verilerin boyutlarını görebilirsiniz.
Table Scan
Tablo üzerinde herhangi bir index yer almadığında karşılaşacağımız operatördür. Tüm tabloyu tarayarak istenilen sonucu getirir. Küçük tablolarda performans olarak büyük farklar yaratmayacaktır. Fakat tüm tabloyu gezdiği için I/O ve CPU kullanımı yüksektir. Bu sebeple büyük tablolarda performans açısından karşılaşmak istemediğimiz bir durumdur. Tabloya atılacak bir clustered index ile sorgu performansı iyileştirilebilir.

Clustered Index Scan
Yukarıda kullanmış olduğumuz sorgu için tabloda herhangi bir index olmadığından Table Scan yaptığını gördük. Çözüm olarak ise Clustered Index tanımlayabileceğimizi söylemiştik. Şimdi bu tabloya bir Clustered Index tanımlıyorum ve tekrardan aynı sorgu için Execution Plan’a bakıyorum.

Bu kez sorgu için Clustered Index üzerinden Scan yaparak sonucu getirdi.
Clustered Index Scan, tabloya herhangi bir koşul belirtmediğimizde ya da koşul attıysak eğer, index tanımladığımız kolonu değil başka bir kolonu koşulumuzda belirttiğimizde karşılaşacağımız operatördür.
Örnek vermek gerekirse, ben Clustered Index için “BusinessEntityID” kolonunu seçtim ve bu kolon üzerinden Clustered Index tanımladım. Yukarıdaki resimde görmüş olduğunuz üzere herhangi bir koşul belirtmedim ve Clustered Index Scan yaptı.
Şimdi bir koşul vererek aynı tabloya sorgu atalım. Fakat bu sorgu için koşulumuzu “BusinessEntityID” kolonu için değil başka bir kolon seçerek veriyorum.

Görmüş olduğunuz gibi sorgumuzu düzenleyip Execution Plan’ı incelediğimizde yine Clustered Index Scan yaparak bize sonucu getirdi.
Bu operatörün de performans anlamında Table Scan’dan çok büyük farkları bulunmamaktadır. Çünkü yine tablomuzu tarayarak sonuçları getirmektedir ve benzer sayılarda okuma yapacaktır. Çözüm olarak indexleri incelemek faydalı olacaktır.
Peki koşulumuzu tanımlamış olduğumuz index üzerinden yani “BusinessEntityID” kolonu üzerinden vermiş olsaydık nasıl bir durumla karşılaşacaktık ?
Clustered Index Seek
Clustered Index Seek, üzerinde Clustered Index tanımladığımız kolonu koşul olarak kullandığımızda karşılaştığımız operatördür.
Yukarıdakine benzer şekilde aynı tablo üzerindeki sorgumuzu düzenleyip koşul verirken “BusinessEntityID” kolonunu kullandığımızda bu kez Index Seek yaparak bize sonuçları getirecektir.

Clustered Index Seek yaparken, tüm tabloyu değil de verdiğimiz koşula göre arayacağı için performans bakımından daha avantajlıdır. Görmek istediğimiz, performans dostu operatördür.
Bazı durumlarda sadece tek koşul değil birden çok koşul vererek komplike sorgular kullanabiliyoruz. Böyle bir durumda hem clustered index oluşturduğumuz kolon hem de başka bir kolon kullanıp bunları and/or operatörleri ile bağlarsak nasıl bir sonuçla karşılaşacağız ?
AND operatörü ile başlayalım. Böyle bir durumda her iki koşulu da sağlaması gerektiği için, koşulu Clustered Index üzerinden sorgular buradan bir key alarak diğer kolonları da bunun üzerinden getirir. Kısacası sorgumuz Clustered Index Seek üzerinden giderek istediğimiz sonuçları getirecektir.
OR operatörüne bakacak olursak eğer, bu durumda da iki koşuldan birini sağlaması yeterli olacağı için iki koşula da bakmak durumundadır. Dolayısıyla Clustered Index olan kolon üzerinden Index Seek yapsa da diğer kolon için Index Scan yapacağından sorguyu Index Scan üzerinden getirecektir.
Burada her iki mantıksal operatör için de dikkat edilmesi gereken nokta, diğer kolon üzerinde NonClustered Index olmamasıdır. Eğer NonClustered index mevcutsa farklı durumlar gelebilir. Böyle bir durumu yazının devamında inceleyeceğiz.
Clustered Index kısmında önemli gördüğüm ve paylaşmak istediğim bir diğer durum ise, sadece Clustered Index Scan/Seek kullanılarak gelen sorgu sonucunda istediğimiz kolonların herhangi bir öneminin olmaması. Yani Clustered Index Seek yapacak olduğunda tüm kolonları çekmek ile sadece belirli birkaç kolonu görmek arasında execution planda bir fark olmayacaktır. Tabi özellikle belirtmek istiyorum, temel seviyede sorgular join yapılarının vs. olmadığı durumlar için geçerli. Eğer sorgumuz Clustered Index üzerinden değil de NonClustered Index üzerinden gidecek olursa, böyle bir durumda gösterilmek istenen kolona göre Execution Plan değişebilmektedir.(Key Lookup yapmak gibi.)
NonClustered Index Scan-Seek
Burada iki başlığı birlikte inceleyeceğiz. Çünkü burada NonClustered Scan için verilecek örnek sorgular tablonuz üzerindeki Clustered Index’e gidebilir ya da NonClustered Seek yapabilir. Dolayısıyla tablo üzerindeki indexlemeye göre farklılıklar göstereceğinden, NonClustered Index Scan ile farklı sorgular sonucunda karşılaşabiliriz.
NonClustered Index Seek ise bir kolon üzerinde NonClustered index tanımlı olduğunda, sadece o kolonu getirmesini istediğimizde ve o kolonu koşul kısmında belirttiğimizde karşılaşacağımız operatördür.
Burada dikkat edilmesi gereken nokta, koşul olarak verdiğimiz kolon için NonClustered Index Seek yapacak olmasıdır. Fakat sorgu sonucunda başka kolonları da getirmesini istiyorsak burada NonClustered Index Seek yanında bir de Key Lookup işlemiyle karşılaşabiliriz.
Bunu bir sorgu üzerinden inceleyecek olursak,
Tablomuz üzerinde CreditCardID kolonunda bir NonClustered Index tanımlı. Sorgumuzda yer alan koşulda da bu kolonu belirttik. İlgili kolonu getirmesini istediğimizde NonClustered Index Seek yaparak bize sonucu döndürdü.

Sorgumuzda ihtiyaçlar değişti ve sadece CreditCardID kolonu değil yanında bir de ModifiedDate kolonunu getirmek istediğimizde Execution Plan değişecek ve Key Lookup da yapacaktır. Burada CreditCardID bilgisini NonClustered Index Seek üzerinden getirip, indexte yer almayan kolon için Clustered Index’e gider ve Key Lookup yaparak sonucu döndürür.

Görüldüğü üzere maliyetin yarısını Index Seek için kullanırken diğer yarısını da Key Lookup için kullanıyor. Sonrasında bu outputları Nested Loops ile birleştirerek bize sonuçları getiriyor. Burada kullanmış olduğumuz sorgu özelinde Key Lookup maliyeti fazla olduğundan, Key Lookup yapmasına sebep olan ModifiedDate kolonunu NonClustered Index’e include olarak ekleyebiliriz. Getirmesini istediğimiz kolonların tümünü NonClustered Index üzerinden getireceği için ve koşulumuz da bu NonClustered Index içinde yer alan kolonlardan birisi olduğu için Index Seek yapacaktır.
Key Lookup
Sorgumuz sırasında koşul olarak NonClustered Index tanımlı bir kolon verdiğimizde ve bu kolonda yer alan verileri görmek istediğimizde, NonClustered Index Seek yaparak sorgu sonucunu getireceğinden bahsettik. Koşulda belirttiğimiz kolon aynı kalmak kaydıyla, o kolon dışında bir kolon görmek istediğimizde ya da tüm kolonları seçtiğimizde burada farklı bir yoldan sonuçlarımızı getirecektir.
Şimdi biraz Key Lookup kavramını inceleyelim.
NonClustered Index yapısı gereği index oluşturulmuş kolonun mantıksal yolunu tutmaktadır. Bu kolonun verilerini getirmesini istediğimizde tutulmuş olan yol üzerinden giderek veriye ulaşır. Fakat biz bu kolonla birlikte başka bir kolonu da sorgulamak istediğimiz için öncelikle o koşula uyan verileri bulur, o veriler için bir anahtar tutar. Daha sonrasında bu anahtar değer üzerinden diğer kolona giderek oradaki verileri alır ve sonucu yansıtır.
Kısaca Key Lookup, where clauseda vermiş olduğumuz kolon için bir NonClustered index mevcutsa ve Select ifadesiyle çağırdığımız diğer kolonlar için herhangi bir index yoksa (include edilmemişse) Clustered Index kullanıp onun üzerinden verileri getirmesidir.
Çözüm olarak ise, sorgu çok sık kullanılıyorsa Key Lookup yaptığı kolonu belirleyip NonClustered indexte include edebilirsiniz.
Şimdi bunu bir örnek üzerinde inceleyelim.
Senaryo gereği öncelikle sorgumuzda NonClustered Index Seek yapacak basit bir sorgu yazalım.

Görüldüğü üzere koşulda CreditCardID kolonu var ve Select işlemini CreditCardID için yapıyoruz. Sonuç olarak NonClustered Index Seek yaparak veriyi getiriyor.
Koşul olarak CreditCardID kaldığında fakat Select işlemini hem CreditCardID hem de ModifiedDate kolonu için yaparsak nasıl bir yol izleyecek bakalım.
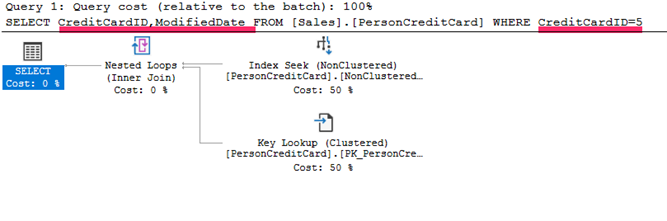
Bu kez sorgumuzda CreditCardID kolonu için yine Index Seek yaptı. Ama index tanımlı olmayan ModifiedDate kolonu için Key Lookup yaptı. Clustered index kullanarak bu kolon için bilgileri aldı ve sonucunda bu iki operatörü joinleyerek bize sonucu getirdi.
Biraz daha detaya inecek olursak CreditCardID kolonu için NonClustered Index kullanarak Seek işlemi gerçekleştirdiğini söylemiştik.

Buradan almış olduğu anahtar değer ile Clustered Index’e giderek diğer kolonu getirdiğini görelim.

Key Lookup yapmasını engellemek için ModifiedDate kolonunu NonClustered Index’e include edip sorgumu yeniden çalıştırıyorum.

Aynı sorgu için bu kez Key Lookup yapmadan, NonClustered Index Seek ile verileri direkt olarak getirdi.
RID Lookup
Yukarıda Key Lookup yapısından bahsederken NonClustered Index Seek yapıp, diğer kolonlar için Clustered Index üzerinden giderek verileri getirdiğini ifade etmiştik. Fakat aynı senaryoda Clustered Index yok ise sonuçları Key Lookup yapmadan nasıl getirecek ?
Yeni bir tablo oluştururken Unique bir kolon tanımlamak ve bu kolon için bir PK tanımlamamız performans ve hız açısından önemli bir detaydır. Oluşturduğumuz bu PK, index listesi altında Clustered Index olarak işaretlenir ve sadece 1 tane oluşturulabilir.
Senaryo gereği, Clustered Index yanlışlıkla silindi ya da hiç oluşturulmadıysa ve tablomuzda NonClustered Index hala mevcutsa bu durumda Key Lookup yapamayacaktır. Çünkü elimizde bir Clustered Index yok. İşte bu noktada NonClustered Index kullanarak Index Seek yapmaya devam edip, diğer kolon için Key Lookup değil RID Lookup yapacaktır.
Bunu yine aynı örnek üzerinden ilerlemek amacıyla BusinessEntityID kolonu için tanımlı Clustered indexi siliyorum ve BusinessEntityID kolonu ile birlikte CreditCardID kolonuna sorgu atıyorum.

Görüldüğü üzere CreditCardID kolonu için Index Seek yaparken, BusinessEntityID kolonu için RID Lookup yaptı ve iki operatörü joinleyip bize sonucu döndürdü.
Bu operatör için çözüm olarak da tabloda Clustered Index tanımlayabilirsiniz. Böylece hem performans hem de sorgulama hızınızı artırabilirsiniz.
SORT
Sorgularımızda Order By kullandığımızda karşımıza çıkan operatördür. Öncesinde koşullara uyan verileri indexler yardımıyla getirir, bu operatörleri joinler ve son olarak sıralayarak sonuçları gösterir. Veri boyutuna bağlı olarak maliyeti değişecektir.
Bir örnek üzerinden inceleyelim.
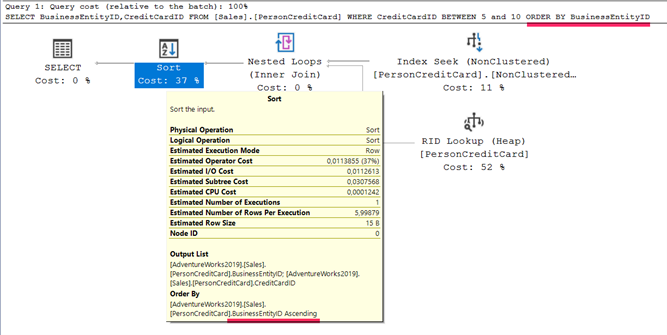
Bu execution planı inceleyecek olursak, CreditCardID kolonu üzerinde bir NonClustered index olduğu için bu kolonda Index Seek yaptı. Clustered indexi bir önceki örnekte kaldırdığımız için şu anda diğer kolon olan BusinessEntityID kolonunu getirmek adına RID Lookup yaptı. Daha sonrasında bu iki ayrı operatörden gelen outputlar için join işlemi gerçekleştirdi. Ve son olarak bu datalar üzerinde sıralama yapmak için SORT operatörünü kullanarak bize sonucu getirdi.
Son operatörümüz olan SORT operatörünü de örnek sorgu üzerinden inceledik ve yazımızın sonuna geldik.
Bu yazımızda senaryolara uygun ve komplike olmayan sorgular üzerinden execution plan nedir, nasıl okunmalıdır, hangi durumlarda hangi operatörlerle karşılaşabileceğimize değinmek istedim. Bütün örnekler ise AdventureWorks veri tabanı üzerinde gerçekleştirildi. Çalıştığımız firmalarda indexleme yapısına ve sorgu örneklerine göre execution plan değişebilecek olsa da genel anlamıyla operatörleri aktarmaya çalıştım.
Umarım faydalı bir yazı olmuştur.
Hoşça kalın.