

SOLR Nedir ve Nasıl Kurulur
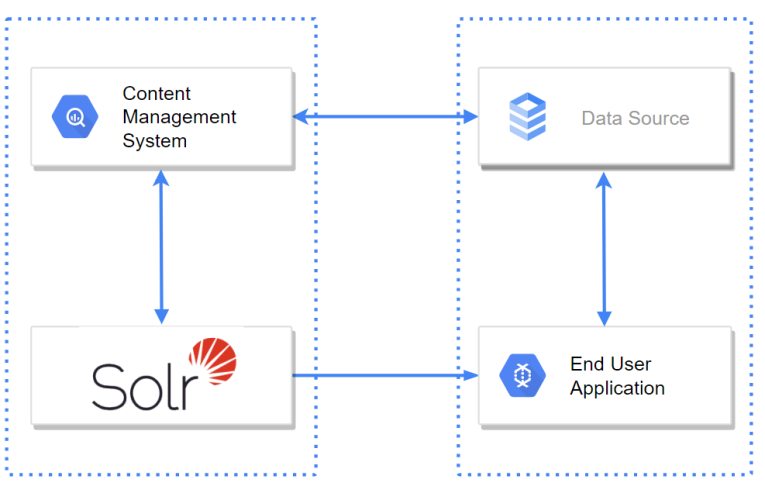
Solr yazılımcıların program geliştirmesini kolaylaştırmak amacıyla yazılmış gelişmiş arama kriterlerine sahip yüksek hızda veri sonuçlarını sağlamak amacını taşıyan bir platformdur. Java programlama dili tabanlı olan Solr, Apache Lucene projesinden faydalanılarak geliştirilmiştir. Arama ve Indexleme hizmetine bir çözüm olarak en hızlı gelişen Apache çözümlerinden birisi olmuştur.
Solr Http sorgulamalar ile sonuç döndürmektedir. Bu sayede hangi yazılım dili kullanırsanız kullanın, Java kurabildiğiniz her ortamda çalışabilmektedir. Mobil cihazlardan kullandığımız tarayıcılara kadar, zengin bir erişim ortamının Solr’ı kullanabileceği anlamına gelir. Sorgulama sonuçlarınız size yapılandırılmış bir veri olarak geri dönmektedir. (Structered Data) Ör: JSON, XML, CSV gibi.. Verilerin tutulduğu şema yapısı çok esnektir bu sayede her türden veri Solr içerisinde barındırılabilir. Sorgulama ve sıralama işlemleri için basit bir sonuç çağırma işlemi yada karmaşaya sahip bir sorgu fark etmeksizin farklı veri tiplerini size baş döndürücü bir hızda sonuç döndürür. Field’lar (yada column diyebiliriz) için özel fonksiyonlar çalıştırabilir, güçlü analizler gerçekleştirebilirsiniz. Solr genellikle web sitelerinde arama çubuklarında kullanılmaktadır.
Document, Field ve Schema Tasarımı
Solr’un en büyük özelliği basit olmasıdır. Solr’ın temel birimi Document‘dır. Document herhangi birşeyi barındıran bir veri kümesidir. Örneğin bir kişiyle ilgili bir Document, kişinin adını, soyadını, en sevdiği rengi ve ayakkabı numarasını içerebilir. Yada kitapla ilgili bir Document, başlık, yazar, yayın yılı, sayfa sayısı vb. içerebilir. Solr’ın yapısında Document farklı veri türlerinden (Field) oluşmaktadır. Field’ların tanımı son derece esnektir. Örneğin ad ve soyad alanı metindir. Bir ayakkabı boyutunun Field’ı 43 veya 44,5 gibi değerleri içerebilmesi için ondalık sayı türünde bir değer olabilir. Field türünü belirterek, bir Field’ın içerdiği veri türünü Solr’a belirtebilirsiniz. Field türü, Solr’a Field’ın nasıl yorumlanacağını ve nasıl sorgulanabileceğini söyler. Ör: Ayakkabı boyutu Field’ını ondalık sayı yerine metin alanı olarak tanımlayabilirsiniz. Ancak alanlarınızı doğru tanımlarsanız, Solr bunları doğru bir şekilde yorumlayabilir ve kullanıcılarınız sorgu yaptıklarında daha iyi sonuçlar alacaklardır. Document eklediğinizde, Solr Document Field’larındaki bilgileri alır ve bu bilgileri bir dizine(Index’e) ekler. Bir sorgulama gerçekleştirdiğinizde, Solr ilgili Index’e hızlıca bakabilir ve eşleşen Document’leri hızlıca döndürebilir.
Solr, Indexlemesini yapması gereken Field’lar ile ilgili değişken türlerinin ayrıntılarını bir şema dosyasında saklar. Bu şemanın saklandığı dosyanın adı managed-schema.xml ve schema.xml olabilir. İki dosya arasında temel fark birisi kurulum gerçekleştirildiğinde varsayılan olarak nasıl bir şema oluşturacağınız diğerinde ise mevcut kurulumdaki şema yapısını nasıl değiştireceğinizdir.
Kurulum
Öncelikle JAVA sistemimizde kurulu olması gerekmektedir. Yukarıdaki paragraftada belirttiğim gibi Java’nın kurulu olduğu her ortamda Solr çalışabilmektedir. Java ortamınızda kurulu değilse kurulumunu tamamlayınız. Aşağıda belirtmiş olduğum komutla birlikte Java’nın versiyonunu kontrol edelim;
java -version
Burada yer alan kaynaktan “Binary Relases” kısmından son sürümü indirelim.

Solr’ın çalışacağı ortamda konumlandıracağımız alanda .tgz dosyası içerisinden çıkarıp konumlandıralım. Ben C diski altında SQLEKIBI isminde bir klasör açıp konumlandırmayı tercih ettim. İsimlendirmedeki fazlalıkları temizledim.

“C:\SQLEKIBI\solr\bin” dizine giderek “Command Prompt” açarak aşağıdaki komut ile Solr’ın çalışmasını sağlıyorum. Artık Solr çalışmaya başladı. Commant Prompt’u kapattığınızda Solr’da kapanacağını unutmamalısınız.
solr start
Ortamınızda çalışan Solr’ın hakkında sürüm ve bellek kullanımı gibi temel bilgileri getirmek için aşağıdaki komutu kullanabilirsiniz;
solr status
Daha sonra Solr arayüzüne ulaşmak için kullandığımız tarayıcımıza aşağıdaki adres üzerinden erişim sağlıyoruz. Solr benim ortamımda 8983 nolu Port’da çalıştığı için localhost’un sonuna ekliyorum.
http://localhost:8983/
Document’larımızı ekleyeceğimiz bir Core oluşturuyoruz. Core veritabanı olarak düşünebiliriz.

Solr arayüzünden kontrol sağladığımda Core’un oluştuğunu görüyorum. Artık veri girişi ve arama işlemleri gerçekleştirebilirim.

Yeni bir Document ekleme işlemi gerçekleştirelim;

Sorgulamayı gerçekleştirdiğimiz eklediğimiz Document’i Query alanından sorgulayarak sonucu gözlemliyoruz.

Solr kurulumu ve kullanımı çok kolay olmakla birlikte analiz gerçekleştirildiğinde ise cevapları çok hızlı sağlamaktadır. Java’nın gücünden faydalandığı için Garbage Collector yapısı ile birlikte kaynak kullanım düzeyi optimum olarak kalmaktadır. Bu sayede sınırlı kaynaklar içerisinde optimum kullanım ile maksimum verim alınabilmektedir.
Kaynakça
https://solr.apache.org/guide/solr/latest/getting-started/documents-fields-schema-design.html